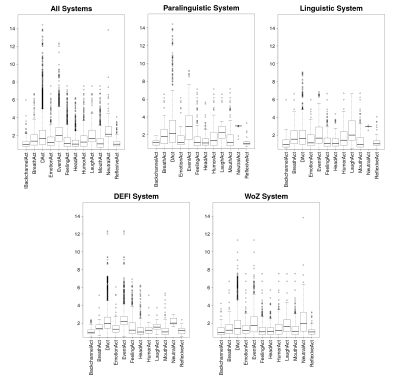
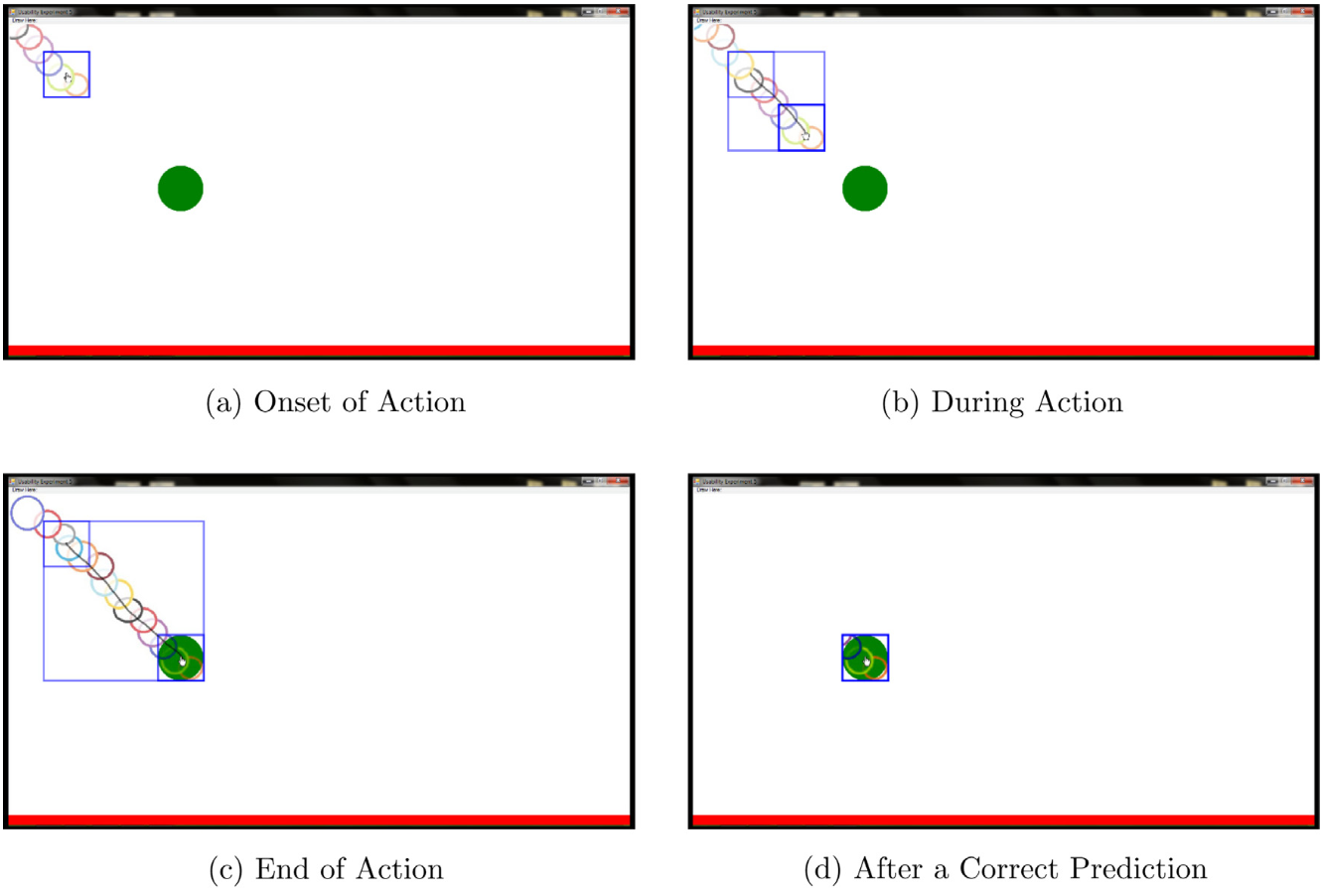
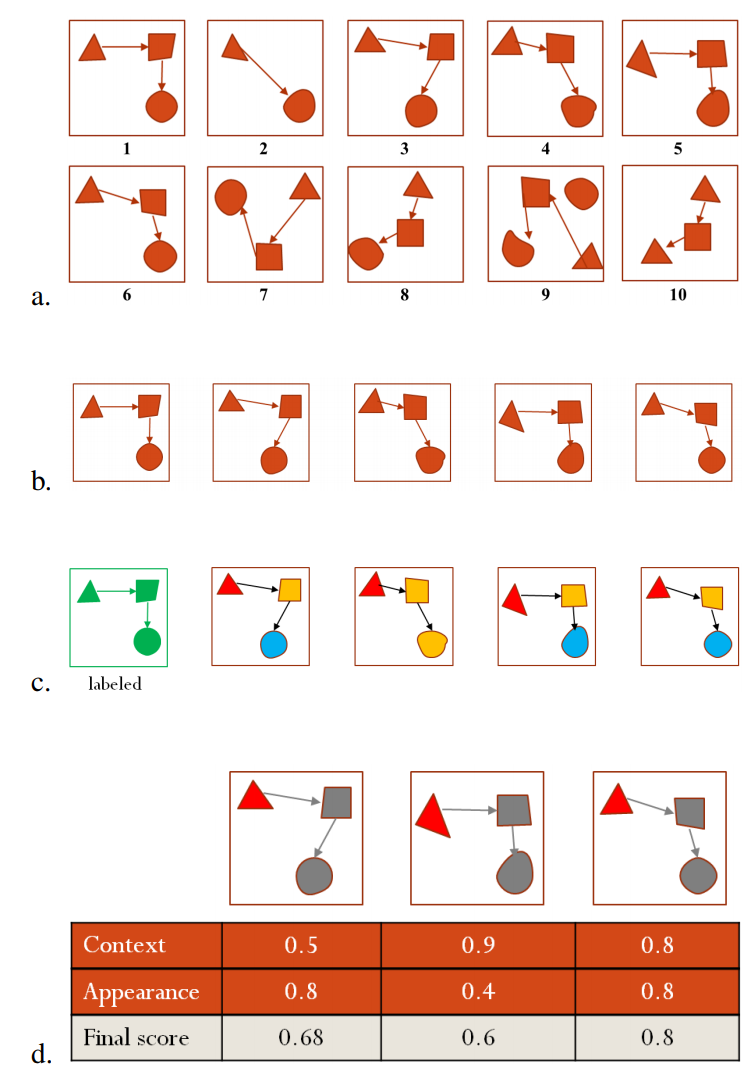
Human eyes exhibit different characteristic patterns during different virtual interaction tasks such as moving a window, scrolling a piece of text, or maximizing an image. Human-computer studies literature contains examples of intelligent systems that can predict user’s task-related intentions and goals based on eye gaze behavior. However, these systems are generally evaluated in terms of prediction accuracy, and on previously collected offline interaction data. Little attention has been paid to creating real-time interactive systems using eye gaze and evaluating them in online use. We have five main contributions that address this gap from a variety of aspects. First, we present the first line of work that uses real-time feedback generated by a gaze-based probabilistic task prediction model to build an adaptive real-time visualization system. Our system is able to dynamically provide adaptive interventions that are informed by real-time user behavior data. Second, we propose two novel adaptive visualization approaches that take into account the presence of uncertainty in the outputs of prediction models. Third, we offer a personalization method to suggest which approach will be more suitable for each user in terms
of system performance (measured in terms of prediction accuracy). Personalization boosts system performance and provides users with the more optimal visualization approach (measured in terms of usability and perceived task load). Fourth, by means of a thorough usability study, we quantify the effects of the proposed visualization approaches and prediction errors on natural user behavior and the performance of the underlying prediction systems. Finally, this paper also demonstrates that our previously-published gaze-based task prediction system, which was assessed as successful in an offline test scenario, can also be successfully utilized in realistic online usage scenarios.
Keywords:
Implicit interaction, activity prediction, task prediction, uncertainty visualization, gaze-based interfaces, predictive interfaces, proactive interfaces, gaze-contingent interfaces, usability study
Authors: Çağla Çığ and T. M. Sezgin
Read the full paper.
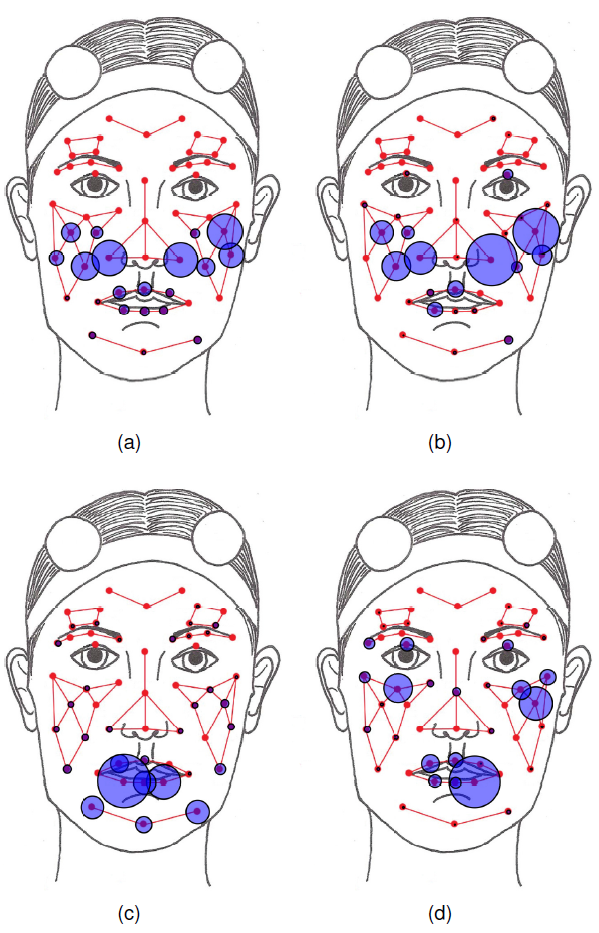
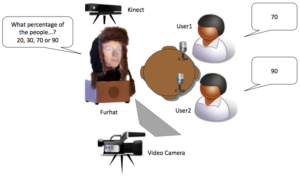
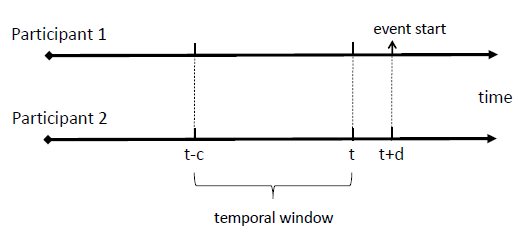 Head-nods and turn-taking both significantly contribute conversational dynamics in dyadic interactions. Timely prediction and use of these events is quite valuable for dialog management systems in human-robot interaction. In this study, we present an audio-visual prediction framework for the head-nod and turntaking events that can also be utilized in real-time systems. Prediction systems based on Support Vector Machines (SVM) and Long Short-Term Memory Recurrent Neural Networks (LSTMRNN) are trained on human-human conversational data. Unimodal and multi-modal classification performances of head-nod and turn-taking events are reported over the IEMOCAP dataset.
Head-nods and turn-taking both significantly contribute conversational dynamics in dyadic interactions. Timely prediction and use of these events is quite valuable for dialog management systems in human-robot interaction. In this study, we present an audio-visual prediction framework for the head-nod and turntaking events that can also be utilized in real-time systems. Prediction systems based on Support Vector Machines (SVM) and Long Short-Term Memory Recurrent Neural Networks (LSTMRNN) are trained on human-human conversational data. Unimodal and multi-modal classification performances of head-nod and turn-taking events are reported over the IEMOCAP dataset.