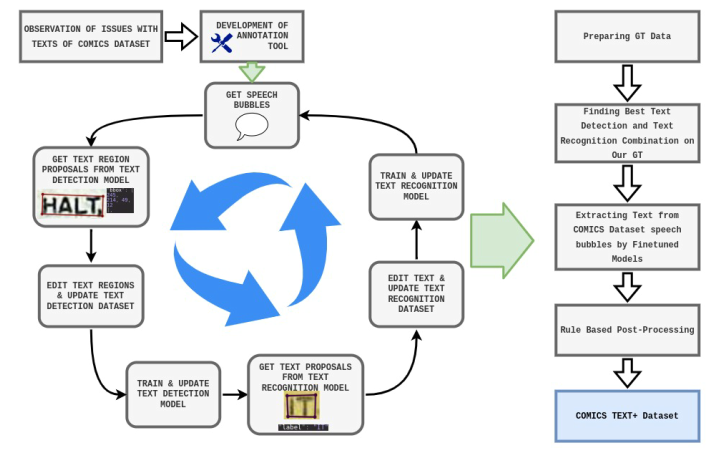
This study focuses on improving the optical character recognition (OCR) data for panels in the COMICS dataset, the largest dataset containing text and images from comic books. To do this, we developed a pipeline for OCR processing and labeling of comic books and created the first text detection and recognition datasets for western comics, called “COMICS Text+: Detection” and “COMICS Text+: Recognition”. We evaluated the performance of state-of-the-art text detection and recognition models on these datasets and found significant improvement in word accuracy and normalized edit distance compared to the text in COMICS. We also created a new dataset called “COMICS Text+”, which contains the extracted text from the textboxes in the COMICS dataset. Using the improved text data of COMICS Text+ in the comics processing model from resulted in state-of-the-art performance on cloze-style tasks without changing the model architecture. The COMICS Text+ dataset can be a valuable resource for researchers working on tasks including text detection, recognition, and high-level processing of comics, such as narrative understanding, character relations, and story generation. All the data and inference instructions can be accessed in https://github.com/gsoykan/comics_text_plus.
Key words: Comics text dataset, OCR on comics, The Golden Age of, Comics, Text detection on comics, Text recognition on comics
Authors: Soykan, G., Yuret, D., and T. M. Sezgin