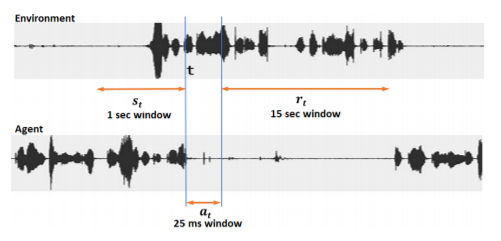
We present a novel method for training a social robot to generate backchannels during human-robot interaction. We address the problem within an off-policy reinforcement learning framework, and show how a robot may learn to produce non-verbal backchannels like laughs, when trained to maximize the engagement and attention of the user. A major contribution of this work is the formulation of the problem as a Markov decision process (MDP) with states defined by the speech activity of the user and rewards generated by quantified engagement levels. The problem that we address falls into the class of applications where unlimited interaction with the environment is not possible (our environment being a human) because it may be time-consuming, costly, impracticable or even dangerous in case a bad policy is executed. Therefore, we introduce deep Q-network (DQN) in a batch reinforcement learning framework, where an optimal policy is learned from a batch data collected using a more controlled policy. We suggest the use of human-to-human dyadic interaction datasets as a batch of trajectories to train an agent for engaging interactions. Our experiments demonstrate the potential of
our method to train a robot for engaging behaviors in an offline manner.
Key Words:
human-robot interaction, engagement, backchannels, reinforcement learning.
Authors: Nusrah Hussain, Engin Erzin, T. Metin Sezgin, and Yücel Yemez